May 30, 2026
Tools That Track Competitor AI Presence Across ChatGPT and Claude (2026)
Compare manual, API-based, and automated tools for tracking competitor visibility across ChatGPT, Claude, Perplexity, and Gemini. Learn which platforms solve cross-model measurement.



Conversational AI platforms now answer buyer questions that once drove search traffic, making competitor visibility across ChatGPT, Claude, and Perplexity a measurable channel.
Traditional analytics miss how AI platforms recommend brands in conversational responses, creating blind spots when competitors gain citation share you cannot see.
Key Takeaways
- Cross-platform AI competitor tracking measures mention frequency, citation position, share of voice, and sentiment across ChatGPT, Claude, Perplexity, and other LLMs
- Manual tracking remains viable below 50 prompts per week and five competitors; above that threshold, API-based or automated platforms become operationally necessary
- Most AI visibility tools treat ChatGPT and Claude as baseline coverage, while Perplexity and Gemini support distinguishes multi-model trackers from single-platform tools
- Free tiers exclude competitive benchmarking and cap query volumes, making them suitable only for validation rather than ongoing competitive intelligence
- Share of voice normalizes competitive presence across platforms with different citation behaviors and probabilistic response variance
Cross-platform AI competitor tracking is the practice of monitoring mention frequency, citation position, share of voice, and sentiment across ChatGPT, Claude, Perplexity, and other LLMs to identify competitive gaps and model-specific biases that single-platform monitoring cannot detect.
Mention Frequency Vs. Citation Quality
Being named in a response is not the same as being cited as the authoritative source. Mention frequency counts how often a brand appears in AI-generated answers, but citation position — whether the brand's content is linked as a supporting reference, and where that citation appears in the response — reveals trust. AI engines assign different weights to sources: Gemini often favors official websites[1] because it is grounded in Google Search, while ChatGPT relies on an external retrieval layer[1] with industry-specific variance. A brand mentioned fifth without attribution holds less competitive value than a brand cited first with a direct link.
Share of Voice Across Heterogeneous Models
Share of voice normalizes competitive presence when ChatGPT, Claude, and Perplexity have different citation behaviors and probabilistic response variance. Defined as the percentage of competitive prompts where your brand appears[3], share of voice accounts for the fact that two competitors may receive identical mention counts on ChatGPT but wildly different counts on Perplexity if one has fresher content. Traditional analytics miss this because they cannot capture how often — and how authoritatively — a brand appears[3] across heterogeneous models. Yext Research analyzed 17.2 million AI citations[1] and found that AI search visibility depends on retrieval logic[1], not just content quality. Without cross-platform tracking, brands optimize for one model's preferences while losing ground on others.
Why Single-Platform Monitoring Creates Blind Spots
Monitoring only ChatGPT misses Claude's official-site preference and Perplexity's recency bias. AI assistants prefer fresher content: cited URLs average 1,064 days old versus 1,432 for traditional search results — 25.7% newer[2]. A brand invisible on Perplexity because its last update was six months ago may dominate ChatGPT's responses if its domain authority is strong. Single-platform tracking optimizes for one engine's heuristics while competitors capture share of voice on the platforms you are not watching. The four core metrics, mention frequency, citation position, share of voice, and sentiment, must be measured per-platform to surface these blind spots before they become market-share losses.
Understanding what cross-platform tracking measures clarifies why existing analytics infrastructure cannot capture it.
Why Traditional SEO Tools Miss Multi-Llm Competitive Intelligence
Traditional Analytics Cannot Capture AI Citations
Google Analytics and standard rank trackers were built for clickstream data and SERP positions, but conversational AI responses don't generate either[4]. When ChatGPT or Claude recommends a competitor in response to "best project management tools," traditional analytics dashboards show zero visibility even when your brand is cited multiple times. The gap is structural: AI engines produce non-deterministic, conversational answers where visibility doesn't automatically translate to trackable clicks, leaving marketing teams blind to how AI platforms portray their brand versus competitors across purchasing conversations.

Relying on GA4 referral reports to track AI visibility creates a dangerous blind spot. Zero referrals from ChatGPT doesn't mean zero citations, it often means your brand is being discussed but users aren't clicking through, or the AI response satisfied their query without sending traffic. This is why competitive intelligence in the AI era requires purpose-built monitoring that captures mentions, positioning, and sentiment directly from AI-generated responses.
Three Tracking Methodologies: Manual, Api-Based, Automated
Tracking multi-LLM competitive presence falls into three methodologies. Manual spot-checking, querying ChatGPT, Claude, and Gemini yourself, provides immediate visibility but scales poorly beyond a handful of prompts per week. API-based tracking taps direct model APIs to log responses programmatically, offering flexibility but requiring engineering resources and per-token costs that escalate with query volume. Automated monitoring platforms, tools that process more than 400 million prompt insights drawn from real user conversations[5], run hundreds of conversational queries daily across major AI engines, tracking brand mentions, competitor positioning, and citation sources without manual effort. The next section details when each methodology fits your competitive intelligence needs and budget constraints.
These blind spots force teams into one of three tracking approaches, each trading off cost, fidelity, and operational scale.
Core Tracking Methodologies: Manual Vs. Api-Based Vs. Automated Platforms
Manual Tracking: Viable Below 50 Prompts/Week
Manual spot-checking remains viable for small-scale monitoring, teams running fewer than 50 prompts per week while tracking five or fewer competitors can maintain basic visibility through direct queries to ChatGPT, Claude, and Perplexity. This approach requires a single analyst to log responses manually, compare positioning across sessions, and flag shifts in competitor mentions. The operational ceiling is clear: above 50 weekly prompts or when monitoring more than five competitors, manual methods cannot maintain historical trend data or competitive benchmarking without dedicated headcount. Static markets with infrequent product launches may tolerate this cadence; fast-moving B2B SaaS categories typically cannot.
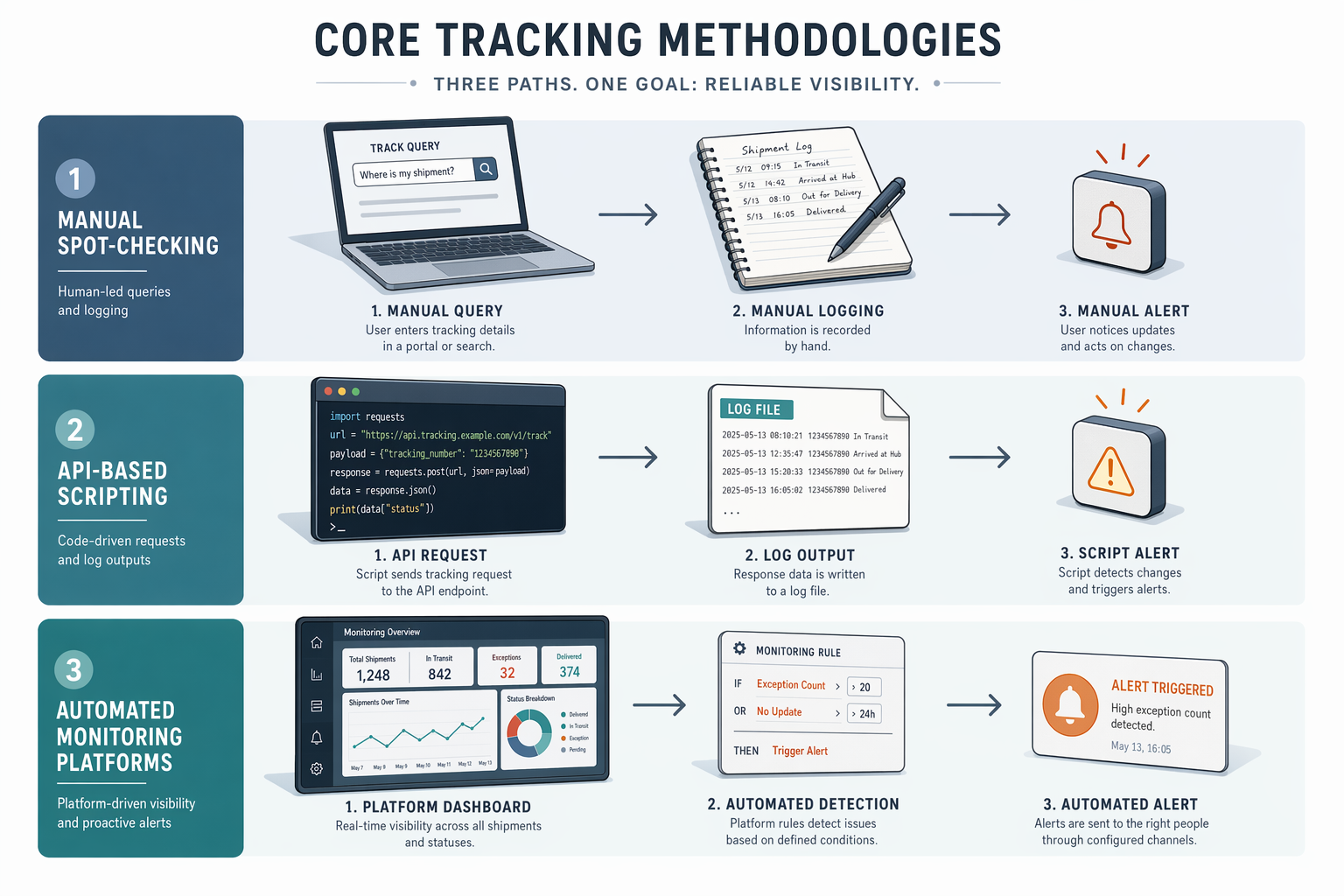
Api-Based Tracking: Approximate but Scalable
API-based tracking queries the ChatGPT API programmatically to run hundreds of prompts in parallel, sidestepping manual logging and enabling historical trend capture. The trade-off is response fidelity: ChatGPT API responses approximate but do not exactly match the consumer UI experience, meaning API-tracked mention rates serve as directional indicators rather than pixel-perfect snapshots of what buyers see. Teams using this methodology accept the approximation in exchange for scalability, running 500 monthly prompts across three competitors becomes operationally feasible, though citation source breakdowns and UI-specific formatting may differ from end-user sessions. This approach suits teams prioritizing volume and trend detection over exact replication of the consumer experience.
Automated Platforms: Scheduled Multi-Model Monitoring
Automated platforms run scheduled queries across ChatGPT, Claude, Perplexity, and Gemini, tracking brand mentions, competitor positioning, and citation sources without manual intervention. Tools segment by query volume and competitive depth, entry-tier platforms starting at $29/month handle single-brand monitoring across limited query sets, mid-tier options from $69 to $99/month add competitive benchmarking and multi-platform coverage, and enterprise platforms above $199/month support agency-scale tracking with custom query libraries. The primary advantage is cross-platform measurement consistency: identical query sets run against all four models on the same schedule, enabling share of voice comparisons and trend analysis that manual or API-only methods cannot sustain. Teams adopting this methodology prioritize operational efficiency and comparative intelligence over hands-on query control.
Even automated platforms differ sharply in which LLMs they monitor, creating coverage gaps that distort competitive benchmarks.
Platform-Specific Coverage Gaps: Chatgpt, Claude, Perplexity, and Google AI Overviews
Chatgpt and Claude: Baseline Coverage
Most AI visibility tools now treat ChatGPT and Claude as the baseline multi-model coverage tier. Tools like Search Visibility track how ChatGPT, Claude, Gemini, and other AI models mention your brand, reflecting the market's shift toward three-LLM minimum expectations. However, platforms differ on whether they monitor free-tier versus paid-tier responses, a distinction that matters when citation behavior and training-data access vary by subscription level. Tools tracking only ChatGPT create competitive blind spots: you may rank first in GPT-4 answers but be absent from Claude's recommendations without visibility into the gap.

Perplexity and Gemini: Extended Coverage
Perplexity and Gemini support distinguishes 'multi-model' tools from single-platform trackers. While ChatGPT and Claude coverage is now table stakes, Perplexity's real-time web indexing and Gemini's Google infrastructure integration introduce unique citation dynamics that baseline tools miss. Google AI Overviews tracking remains a separate workflow in most platforms, despite appearing in the same search results page, AI Overviews draw from a different ranking and citation model than conversational Gemini responses. Cross-platform tools must handle these distinct answer engines independently to avoid conflating share of voice metrics across fundamentally different surfaces.
Coverage Gaps and Their Competitive Impact
Partial coverage means you may win on ChatGPT but lose on Claude without knowing it. Rigorous platforms differentiate themselves through transparent sampling design: one methodology ran 200 structured queries across 8 AI models, ChatGPT, Gemini, Perplexity, Grok, Claude, Copilot, GPT-4o, and GPT-o1 [6], establishing statistical confidence through volume and breadth. When evaluating tools, prioritize those that disclose query counts, model coverage, and sampling methodology. Cross-platform consistency is the key buying criterion, citation behavior varies by model, and no source yet explains how to normalize competitor presence across ChatGPT and Claude when one model favors domain authority while another rewards forum discussions.
Platform coverage alone does not determine fit, pricing structure, benchmarking depth, and query volume limits separate validation tools from enterprise competitive intelligence.
Comparing Automated Monitoring Solutions for Multi-Model Competitor Tracking
Comparison Table: Platforms, Pricing, and Key Features
Automated multi-model tracking platforms differ sharply in platform coverage, competitor benchmarking depth, and pricing structure. The table below compares four dedicated solutions across key decision criteria:
| Platform | Pricing | Platforms Tracked | AI Brand Mention Tracking | Citation/Source Tracking | Competitor Benchmarking | Query Volume Limits |
|---|---|---|---|---|---|---|
| Siftly | Free (manual checks); Starter $79/month; Growth and Scale tiers add coverage; Enterprise adds Claude + unlimited responses | ChatGPT, Google AI Overviews, Perplexity, Gemini, Microsoft Copilot, Grok, DeepSeek, Claude (Enterprise) | Yes | Yes | Yes (free tier: 30-day historical data; Scale tier: multi-competitor workflows) | Free tier capped; Starter 4,500 responses/month; Growth and Scale increase capacity |
| Sight AI | Not publicly disclosed | ChatGPT, Claude, Gemini, Perplexity (based on multi-model framing) | Yes | Yes | Not publicly disclosed | Not publicly disclosed |
| SE Ranking | Not publicly disclosed | ChatGPT, Gemini, Perplexity (based on multi-model framing) | Yes | Not publicly disclosed | Not publicly disclosed | Not publicly disclosed |
| GrowthOS | Not publicly disclosed | ChatGPT, Claude, Gemini, Perplexity (based on multi-model framing) | Yes | Not publicly disclosed | Not publicly disclosed | Not publicly disclosed |
| Profound | Starter $99/month; Growth $399/month; Enterprise custom[7] | ChatGPT, Perplexity, Google AI Overviews; Enterprise up to 10 engines[7] | Yes | Yes | Yes (prompt volume data, GA4 integration[7]) | Starter: ChatGPT only; Growth and Enterprise expand coverage[7] |
Siftly provides thorough monitoring across major AI search engines. The free tier includes competitor tracking with 30-day historical data, while the Scale tier provides competitive benchmarking designed for monitoring multiple competitors simultaneously. Profound positions itself for enterprise teams requiring SOC2 compliance and proprietary prompt volume data[7], starting at $99/month for ChatGPT-only coverage and scaling to $399/month for multi-platform tracking[7]. Both platforms provide citation tracking and share of voice analytics, but differ in pricing transparency and tier structure.
Free-Tier Limitations and Enterprise Scaling
Free tiers cap query volumes and exclude competitive benchmarking, making them suitable only for validation-stage tracking rather than ongoing competitive intelligence. Teams testing AI visibility concepts can run manual checks or limited automated queries to confirm their brand appears in target AI responses, but systematic multi-competitor monitoring requires paid tiers. The most affordable AI visibility tools guide details budget-tier options for startups evaluating entry points.
Enterprise tiers add multi-competitor workflows, expanded platform coverage, and higher query volumes. Profound's Enterprise plan covers up to 10 AI engines and provides SOC2-compliant infrastructure[7], positioning it for regulated industries. Siftly's Enterprise tier adds Claude, unlimited responses, and SSO for security compliance, targeting marketing teams that need cross-functional access without per-seat licensing constraints.
Read-Only Vs. Write-Enabled Tool Architectures
Read-only monitoring tools query AI platforms without API keys or write access, making them privacy-conscious choices for teams uncomfortable granting third-party systems direct LLM credentials. These tools capture visibility snapshots and track mention frequency but cannot test live optimizations or inject test content into AI training workflows. Write-enabled tools require API access and can run A/B tests by submitting optimized content variants, but introduce consent and data-sharing considerations.
The trade-off: read-only architectures prioritize user control and minimize third-party data exposure, while write-enabled tools accelerate experimentation cycles by automating optimization testing. Privacy-conscious teams often prefer read-only monitoring paired with manual content updates, accepting slower iteration velocity in exchange for tighter access control. Teams comfortable with API-based workflows gain faster feedback loops but must verify vendor data handling practices match internal security policies.
How to Choose a Cross-Platform AI Visibility Tool for Your Use Case
Decision Framework: Volume, Competitors, and Resources
Choose your approach based on three factors: tracking volume, competitor count, and team resources. Manual tracking works when you monitor ≤50 prompts per week and track ≤5 competitors, spot-check ChatGPT and Claude with test queries, log responses in a spreadsheet. API-based workflows suit teams with engineering capacity who need custom integrations; build against OpenAI or Anthropic APIs to automate query execution and response parsing. Automated platforms become key when you need broad cross-platform monitoring and competitive benchmarking without engineering overhead, tools like Siftly provide coverage across ChatGPT, AI Overviews, Gemini, and Perplexity with automated monitoring in a single dashboard.
For detailed feature trade-offs across platforms, see our platform buyer's guide.
When to Upgrade From Manual to Automated Tracking
Traditional analytics miss how AI platforms recommend brands in conversational responses. The inflection point hits when historical trend tracking becomes infeasible: maintaining 30-day or 90-day competitive baselines above 50 prompts per week requires automation. Manual checks cannot normalize response variance across models or detect when competitors gain share of voice in fast-moving categories. If your market shifts weekly or your executive team asks "Are we losing ground to Competitor X in Claude?" more than once per month, manual tracking has reached its operational limit, upgrade to daily automated monitoring with competitive benchmarking built in.
Manual tracking offers zero cost and full control but becomes operationally infeasible above 50 prompts per week or when monitoring more than five competitors. API-based solutions scale to hundreds of queries but sacrifice consumer-UI fidelity, ChatGPT API responses approximate but don't exactly match what paid subscribers see.
As AI assistants continue to diversify citation behavior, ChatGPT's retrieval layer, Gemini's official-site preference, Perplexity's recency bias, cross-platform competitive intelligence will require normalized measurement frameworks that no single-platform tool or manual workflow can maintain.
Start tracking your competitor AI presence baseline this week using Siftly's automated multi-model dashboard to identify gaps across ChatGPT, Claude, and Perplexity before your next content sprint.
Frequently Asked Questions
Can I track competitor AI presence manually without paid tools?
Yes, but only below 50 prompts per week and 5 competitors. Teams running fewer than 50 prompts weekly can maintain basic visibility through direct queries to ChatGPT, Claude, and Perplexity. Above this volume, manual tracking cannot maintain historical trends or competitive benchmarking at scale.
Do ChatGPT API responses match what consumers see in the ChatGPT UI?
No, ChatGPT API responses approximate but do not exactly match the consumer UI experience. API-based tracking queries models programmatically to enable historical trend capture, but the trade-off is response fidelity, meaning API tracking is directional rather than pixel-perfect for competitive intelligence.
What's the difference between mention tracking and citation tracking?
Mention tracking counts how often your brand appears in AI responses, while citation tracking identifies when your brand is the attributed source with a URL or reference[1]. Citation tracking captures provenance and authority, not just name recognition, measuring whether your content is linked as supporting evidence[2][3].
Do free tiers of AI visibility tools include competitor benchmarking?
No, most free tiers cap query volumes and exclude competitive benchmarking[7]. Free plans are suitable only for validation-stage tracking rather than ongoing competitive intelligence. Teams testing AI visibility concepts can run manual checks or limited automated queries but lack historical competitor comparison.
Why do I need to track multiple LLMs instead of just ChatGPT?
Because citation behavior differs by model, ChatGPT uses external retrieval, Gemini prefers official sites, and Perplexity skews toward recent content[1]. Single-platform tracking creates competitive blind spots where you may win on ChatGPT but lose on Claude without knowing it[2][3].
Can AI visibility tools measure ROI or pipeline impact?
No, attribution models remain directional rather than offering direct CRM pipeline integration[4][5]. Tools can track citation volume and share of voice across ChatGPT, Claude, and Perplexity but cannot definitively link AI citations to closed deals or revenue attribution.
What is 'share of voice' in the context of AI search?
Share of voice is the percentage of competitive prompts where your brand appears, normalized across multiple LLMs[3]. It accounts for different citation behaviors and probabilistic variance across ChatGPT, Claude, and Perplexity, serving as the cross-platform competitive benchmark[1][2].
Sources
- How ChatGPT, Perplexity, Gemini, and Claude Actually Decide What to Cite - www.yext.com (2026)
- 13 Best AI Visibility & Brand Monitoring Tools in 2026 (Tested) - www.demandsage.com (2026)
- AI search 'Share of Voice': The new SEO battleground - birdeye.com (2026)
- AI Search Monitoring Tools 2026: The Best Platforms to Track Your Brand - www.useomnia.com (2026)
- 10 tools for achieving AI visibility as brands prioritize GEO - venturebeat.com (2026)
- We Tested the 11 Best AI SEO Tools in 2026 (Ranked by LLM Coverage) - tryxlr8.ai (2026)
- 10 Best AI Visibility Tools for B2B SaaS Companies in 2026 - LinkedIn - www.linkedin.com (2026)
Keep Exploring more

Jul 30, 2026
Why Your Brand Doesn't Show Up in AI Chatbot Recommendations
Your product ranks in the top three on Google. The brand site pulls healthy organic traffic, and the paid search ROAS meets target. Yet when a shopper asks Chat

Jul 30, 2026
What Tools Track Brand Performance Across Multiple AI
Your brand is being evaluated by an invisible panel of judges every second. ChatGPT, Gemini, and Perplexity now act as primary answer engines for over 400 milli

Jul 28, 2026
7 Best Answer Engine Optimization Tools for Dominating AI
You have spent months getting a page into the top three organic spots for a major keyword. The content is well optimized. Backlinks are solid.

